Using Search as an ApplicationBy
Kenneth Cooper
Enterprise SharePoint Architect
And
Viji Anbumani
SAI Innovations IncBusiness CaseA department came to IT with a request of a document management system that would allow them to meta-tag document (fig 1.1) and discover the content through advanced search. Our users had four document types that they wanted to start with. Each document type had more then twelve pieces of associated metadata. The metadata within the document type covered just about all the basic column types (single line, check box, single select, multi-select, Numbers, and dates). The security for the document types varied between them.
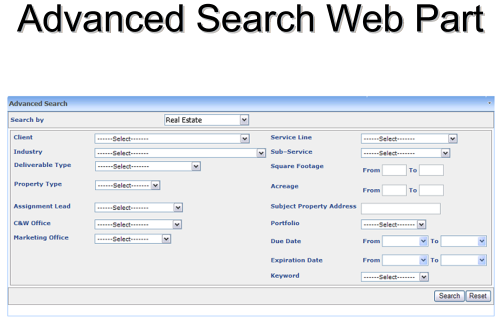
After hearing the initial requirements we knew that SharePoint was a natural fit. So the first thing we did with the users was a discovery phase to hear more of what our users wanted. This phase was also interactive; we informed our users on what SharePoint can do. The first thing that we discovered when showing our user SharePoint was they didn’t like the out of the box advanced search. They really wanted an advanced criteria screen that was reflective of their metadata in look and functionality. They wanted fixed fields that they can populated. The fields also had to have the same functionality as the metadata entry screen. So if they had a multi-select field in the metadata they wanted the same thing within the search criteria screen. The search results they wanted them to come back in a grid. They wanted to have two views for the grid compact and detailed.
The timeline and budget for this project were both short. They wanted to be up and running no later then the first of January. We started the discovery phase mid-September. But they wanted to start uploading content by the first of November. Even though the majority of the project is out of the box we also had to account for rework time.
The ChallengeThe first challenge we needed to resolve was the metadata search on the different document types. After that we needed to do something about the advanced search. The easy solution was to have a custom webpart written to handle the search. Given all the other criteria of their requirements we didn’t have time to push SharePoint aside and do a custom web application. Ninety percent of the functionality was there in SharePoint already that’s why we decided to just do custom webparts.
The PlanThe department handed us excellent requirements for the document types. From pass experience with others projects as the project draws closer and the users start to see the product the rework sometime increases. This is an important factor in SharePoint because there might certain things that the users don’t like and it takes to much effort to rewrite or rework it. First a project plan was created and it had two tracks; structure and portal functionality. The structures were the work that we were doing for the site definitions, content types, and deployment packages.
The structure had to precede the portal work any way so this track was devised to get the users uploading content by November. The custom work like branding and the search web parts were part of the second track. This plan let the users know what they were getting and when.
Side note Don’t assume that your users won’t change their mind about there fields or field types. To help keep our production SharePoint environment clean we go through (development to QA to production). For moving items between these environments there are various methods and tools. We choose to do a site definition and content type features for our document libraries. When using feature we can easily move from environment to environment. We also used import and export site command from stsadmn. The only issue with this is that if you have an error or bad data you have to take care of it once it is deployed. Cleaning up a site in production can prove to be very messy and can cause issues.
The SolutionThe Search Components we used
Content Source –A source of content that you want SharePoint to crawl and index.
Managed Properties – Metadata fields that are defined in SharePoint that are indexed and put into a separate database. These fields can be used in actual search queries.
Scopes – Creates a filtered view of the content in an index based on rules defined within the SSP.
Custom Search Webpart – A custom search criteria screen was built to render the search criteria screen for the users. Another webpart was built to display the results in grid format.
Document Types & Content Types
For each document type we created a content type and a document library (see fig 1.0). The content types were applied to the appropriate document libraries. We leveraged the power of the content type field as a managed property to create our view of the department’s content. A managed property called ‘MPContentType’ was created using content type field. Next a scope was created and rules were added that specified the managed property ‘MPContentType’ as the filter. A rule was added for each content type that we wanted to add to the scope. With the scope in place, queries can be issues; resulting in a query that only queries the specified content types (i.e. Software) within the scope. Now we can isolate the content that we want to search on giving us the base line to our solution (see fig 1 ‘The Big Picture’).
More Managed PropertiesThe next piece of the solution was the additional managed properties that were created. We created a managed property for each piece of metadata that was associated to one of the four content types. This allowed us to do our pinpoint accurate searches on the content. The last piece of the puzzle was the advanced search webpart and the results page. Our users told us that they were only starting with four document types, but a couple of months down the road they want to add more document types. This means the design for the search criteria screen had to grow with user demand.
So that the webpart would be extensible in the future as per one of IT’s requirement was it must work with XML. The webpart takes XML as a parameter and dynamically generates the search criteria screen. That makes this a completely generic solution that can be applied over and over again without having to going back to development. For the webpart we commissioned SAI Innovations a consultant company with a strong background in SharePoint development and solutions.
Through the XML various features can be controlled and the user interface is reflective of the data entry screens. Fields with drop downs and SharePoint lists as data sources can be presented in the same way on the search criteria screen. This gives the end users a lot of flexibility and easy of use so they want have to understand and/or and other operations. Also there’s a drop down for the document type. As the document type is change the fields on the search screen are changed to match the search criteria fields for that document type.
Earlier I mentioned that the document types vary in security requirements. Since SharePoint search engine is security trimmed this did not present a problem to us. We just created SharePoint groups and modified the document libraries security to these groups and configurations.
The search results screen returned the results within a grid per request of our users. For the grid they wanted two modes a summary and a detailed view. On the detailed view it would expand the grid and show the all metadata fields for that type. The results pane also incorporated sorting and paging.
Some issues that we ran into are that the document has to be checked in for that document to be indexed.
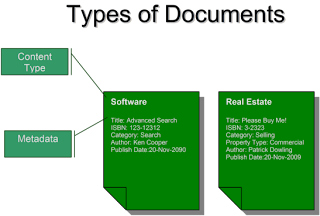
Fig 1.0

Fig 1.1
Fig 1.2
Advanced Search Result Set
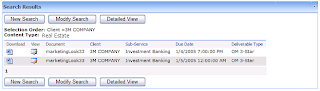
Fig 1.3
When a SharePoint (MOSS) farm is setup a default Shared Service Provider (SSP for short) is created within Central Administration (might vary with WSS). It is within the SSP where the search configurations can be modified. If this is still foreign try to find a good SharePoint Admin.
As items are put into SharePoint there’s a process out there the opens certain files and reads the content and it metadata and writes out what it saw to disk and database (Ok I did skip a few steps but another paper another time). This is called the indexing process (see fig 2). The search functionality can be configured within the Shared Service Provider (SSP).
How does SharePoint know what to indexing? Within the search configuration you’ll see the content sources. A content source is content that you SharePoint to index so that it can be searchable from SharePoint. These content sources are the destination. Content sources can be created for other web sites, files shares, lotus notes, public folders, and SharePoint sites (see fig 3). Once a content source is created you can tell SharePoint to go crawl it. Also crawl schedules can be setup so new content gets indexed periodically. Since our users wanted new content to show up very quickly we created a content source for them and created an incremental schedule to index more frequently. A default content source is already there. Once we add our site to the new content source the old needs to be removed from the default one.
The indexing process also crawl’s the document’s metadata within SharePoint. This is huge piece of the solution puzzle. These metadata fields are store in an actual database. Once they have been indexed this information can be used in queries (SQL like queries). How do I expose this field to SharePoint; by making it a managed property. There would still be some work at the site level but after a few configuration changes you can make these fields show up in advanced search (the out of the box one).
Another awesome thing that you can do within the search configuration is create scopes. Think of scopes as a filtered view of the data that is in the index file. You already see this in most sites already (fig 4). If you have a drop down list in front of the search text box you’ve get scopes! One scope is ‘All Sites’ and usually the other is ‘This Site’. The All sites search all of the SharePoint content but the ‘This Site’ scope only search pertaining to that site. This feature helps scope down our target area that we want to search.
Indexing Engine
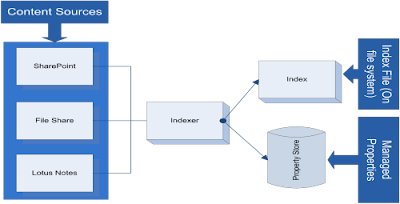
Fig 2

Fig 3
Index and Scope
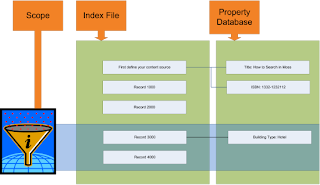
Fig 4